
Diving deep into a lot of projects and education lately spread across a lot of languages and frameworks, but for today, we’re going to have a little bit of fun with some Python 3; web scraping. Data is priceless, having access to the data without manual requirements though, that’s just invaluable.
While we could go the route of something like YellowPages, Yelp, Expedia, or any other sites – let’s have a bit of fun with a sample Python job’s site (not mine, just to clarify, found on GitHub) in order to avoid legal trouble shall we?
WHAT EXACTLY IS WEB SCRAPING?!
If you think of something like weather, you’re going to have services that offer their data for free or via a small monthly fee to access their API (application programming interface) which is a feed of data you can query. If you want to do competitive analysis though, those folks aren’t simply going to hand you over data, so this is where scraping coming into play.
What this means is that you’re figuratively loading a website programatically, running through all of the data, grabbing what you need, and storing or parsing it for your needs. For example, think about the travel industry; we might want to be able to scrape Booking.com or Expedia.com to see their rates across multiple regions, times, different geographical locations via proxy servers, etc, and then compare their rates.
HOW DO WE GO ABOUT PARSING THE SCRAPED DATA?
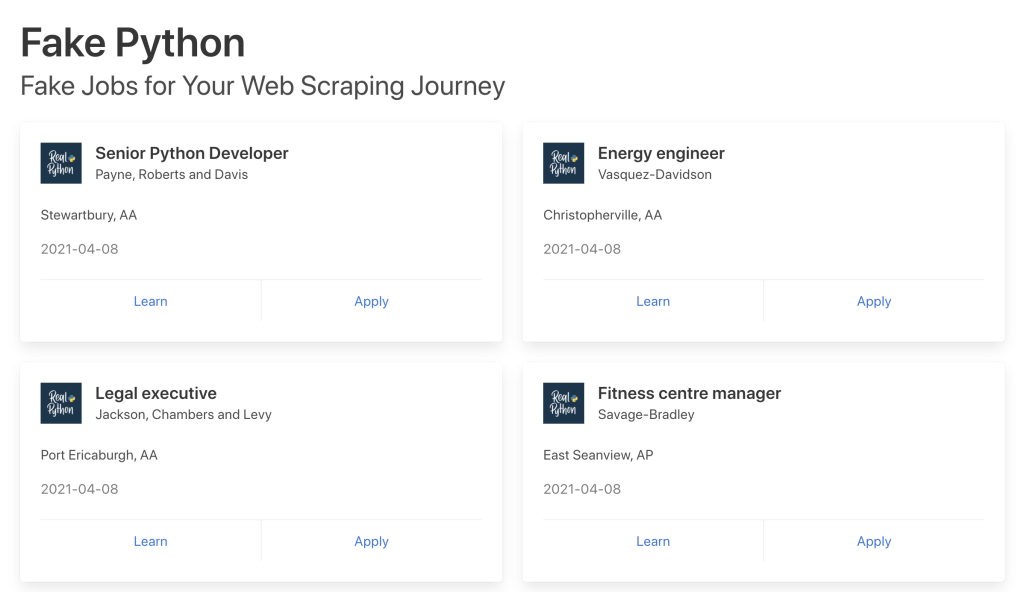
In order for us to start scraping content, we need to actually look at the content and code; each site is going to be completely unique, but there is always a pattern, and always a way to break down the code into data we can parse. Let’s look at one job from the demo site as an example:
<div class="card">
<div class="card-content">
<div class="media">
<div class="media-left">
<figure class="image is-48x48">
<img src="https://files.realpython.com/media/real-python-logo-thumbnail.7f0db70c2ed2.jpg?__no_cf_polish=1" alt="Real Python Logo">
</figure>
</div>
<div class="media-content">
<h2 class="title is-5">Energy engineer</h2>
<h3 class="subtitle is-6 company">Vasquez-Davidson</h3> </div>
</div>
<div class="content">
<p class="location"> Christopherville, AA </p>
<p class="is-small has-text-grey">
<time datetime="2021-04-08">2021-04-08</time>
</p>
</div>
<footer class="card-footer">
<a href="https://www.realpython.com" target="_blank" class="card-footer-item">
Learn
</a>
<a href="https://realpython.github.io/fake-jobs/jobs/energy-engineer-1.html" target="_blank" class="card-footer-item">
Apply
</a>
</footer>
</div>
</div>With this snippet of data, we’re going to want to break it down into a few simple items:
- Image
- Job Title
- Company
- Location
- Date Posted
- Learn More URL
- Apply URL
So how do we go about obtaining this data? If we look at the HTML above, we’ll see that we can break the above into the following:
- Image – figure.image img
- Job Title – h2.title
- Company – h3.company
- Location – p.location
- Date Posted – time
- Learn More URL – .card-footer a
- Apply URL – .card-footer a
PYTHON REQUIREMENTS
Before we dive into some code, we’re going to need to install a few libraries:
To do this, and make things as easy as possible, just run the following inside of your terminal:
# pip3 install fake-useragent
# pip3 install requests
# pip3 install beautifulsoup4…or for simplicity sake, just run the following:
# pip3 install fake-useragent requests beautifulsoup4EXAMPLE SCRAPING CODE
Unlike all the recipe sites with their insanely long preamble, there is no need for long diatribes before showing off the goods, so without more talking (err… writing), let’s just output our working code and then we’ll talk through some of the why’s and what’s in the code.
from fake_useragent import UserAgent
import requests
from bs4 import BeautifulSoup
import json
def main():
ua = UserAgent()
requests.packages.urllib3.disable_warnings()
page_url = "https://realpython.github.io/fake-jobs/"
output_type = "clean" # `json,` `clean,` or `dict`
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'referrer': 'https://google.com',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.9',
'Pragma': 'no-cache',
'User-Agent': ua.random
}
try:
response = requests.get(page_url, verify=False, headers=headers, timeout=25)
if response.status_code == 200:
scraped_results = []
soup = BeautifulSoup(response.content,'lxml')
for item in soup.select('.card'):
title = item.select('h2.title')[0].get_text(strip=True)
company = item.select('h3.company')[0].get_text(strip=True)
location = item.select('p.location')[0].get_text(strip=True)
posting_time = item.select('time')[0].get_text()
for image in item.select('figure.image img'):
posting_image = image['src']
#
for link in item.select('.card-footer a'):
if( link.get_text() == "Apply"):
apply_link = link['href']
elif( link.get_text() == "Learn" ):
learn_link = link['href']
details = {
'title': title,
'company': company,
'location': location,
'posting_time': posting_time,
'image': posting_image,
'apply_link': apply_link,
'learn_link': learn_link
}
scraped_results.append(details)
if(output_type == "clean"):
for job in scraped_results:
print("------------------------------------")
print("Title: %s" % job['title'])
print("Company: %s" % job['company'])
print("Location: %s" % job['location'])
print("Date Posted: %s" % job['posting_time'])
print("Image: %s" % job['image'])
print("Apply Link: %s" % job['apply_link'])
print("Learn More Link: %s" % job['learn_link'])
print("------------------------------------")
elif(output_type == "json"):
response_json = json.dumps(scraped_results)
print(response_json)
elif(output_type == "dict"):
print(scraped_results)
else:
print(":: The URL provided received a 404 Response Code")
except Exception as e:
print(":: There was a problem connecting...")
if __name__ == "__main__":
main()Explaining The Logic & Thought Process
Headers
Why are we using these headers in our example? Accept, Referrer, Accept-Encoding, Accept-Language, etc? Instead of rehasing what has already been written by many folks, in much greater details, please take a look at the following two articles:
- The Most Important HTTP Headers for Web Scraping
- What Are Request Headers And How to Deal with Them When Scraping?
The basic gist is that we’re trying not to get “caught” by the site we’re scraping; the more we can look like a authorized Bot (such as Google) or a “real user” in each of our requests, this limits the amount of blocks we’ll encounter in our automation at scale.
This is also why you see the use of Fake User Agent in the above so that we can randomize this with our request. Take a look at this list for an example of user agents being assigned via the UserAgent function.
Output
The output_type variable offers three simple types in this demo code:
- json – This will combine all of the data from the scraped content and provide you with a single JSON output.
- clean – This will again combine all of the data from the scraped content, but will output within your terminal.
- dict – This will simply print the ‘dict’ (or array) of data parsed from Python.
While this gets the job completed for this demo, at large scale, how you handle your data, storage, etc, can and will be completely different.
BeautifulSoup
This is where it gets fun, and where it becomes unique to each site; you’ll see in this example that we’re looping through each <div> with a class of card as this is where our data can be found; within that, we utilize our classes and information listed above to grab our data such as the following single line of code (which grabs the first h2 with a class of title within the parent container):
title = item.select('h2.title')[0].get_text(strip=True)The only real thing we’re doing here other than grabbing our data via the get_text function is passing strip=True which will ONLY get the human readable text versus any HTML within the container. You can read more about this all at the following links:
Running The Code
Back to the code, copy & paste the above Python code into your favorite editor and save as scraper.py on your local machine; once saved, run the following from within your terminal:
# python3 scraper.pyIf left untouched, with output_type set to clean, this should output a list similar to the following:
------------------------------------
Title: Ship broker
Company: Fuentes, Walls and Castro
Location: Michelleville, AP
Date Posted: 2021-04-08
Image: https://files.realpython.com/media/real-python-logo-thumbnail.7f0db70c2ed2.jpg?__no_cf_polish=1
Apply Link: https://realpython.github.io/fake-jobs/jobs/ship-broker-99.html
Learn More Link: https://www.realpython.com
------------------------------------IMPROVEMENTS
You’ve done it! You’ve officially scraped a website, parsed the data, and outputted the contents – now let’s talk about how we could improve this script to be more useful, powerful, and effective for you and/or your company.
Proxy
At scale, and depending on your speed of attack, it’s going to be very easy to hit a frequent wall – your IP will be blocked or rate limited. While there are many ways around this, the easiest method I’ve used many times is the following Python library:
What this does is allow you to get a dynamic and random proxy for each time you run the script or even on each request; what’s even better is that it takes very little code to implement. You can simply run FreeProxy().get() inside of your script and then pass that to your requests.get as an array.
The only important note right up front is that often times proxies will… die. You’re going to want to write try/except statements into your code upon failure detection so you can get a new proxy and be back up and running (remember – automation is the goal).
Database Storage
Data in our console does very little good other than proof of concept and/or testing; if we’re running analysis on the data, we’re going to want to be able to store it and build/run reports against that data. While we won’t go into great detail on this today, the following two libraries are going to be “must haves” for you (depending on your preferred database):
- MySQL – MySQL-Connector
- MongoDB – PyMongo (Personal Recommendation)
Looping Through URL’s
Much like storing our data, one URL isn’t going to quite cut it; we’ll talk more about dynamic requests in a second, but for now, let’s assume we’ve got something like five pages we want to crawl – we could then do something like the following:
page_urls = [
'https://www.example.com/',
'https://www.example.com/page-2/',
'https://www.example.com/page-3/',
'https://www.example.com/page-4/',
'https://www.example.com/page-5/',
]With that defined, we could then go about the following to parse the content while looping through each URL:
for url in page_list:
response = requests.get(url, verify=False, headers=headers, timeout=25)
if response.status_code == 200:
# Scrape
else:
# Do NothingDynamic Requests
This is where things get more in line with “real world” type situations; most websites are going to be dynamic, they are going to be paginated, they are going to be often updated, and content is going to change. This is why before you ever write a line of code, it’s truly of utmost importance to understand the URL structure, the elements, code on the page, and how to pass that data over to your scraper.
As an example, let’s assume we have the following URL pattern to get started:
In a real world example, we might want to get the rates for each night over the course of the next week; how would we do that? We could write a little bit of code and just build dynamic URL’s on the fly for our data – take a look at the following as a quick & dirty example:
from datetime import datetime, timedelta, date
def main():
base_url = 'https://www.example.com/rates/'
for day in scraper_date_span(date(2022, 7, 1), date(2022, 7, 8),
delta=timedelta(days=1)):
tomorrow = scraper_tomorrow(day)
parse_url = base_url + '?arrival=%s&departure=%s' % (day, tomorrow)
print(parse_url)
def scraper_date_span(startDate, endDate, delta=timedelta(days=1)):
currentDate = startDate
while currentDate <code endDate:
yield currentDate
currentDate += delta
def scraper_tomorrow(start_date):
start_date = datetime.strptime(str(start_date), '%Y-%m-%d')
tomorrow = start_date + timedelta(days=1)
return tomorrow.strftime('%Y-%m-%d')
if __name__ == '__main__':
main()It’s not perfect, but you get the idea; we could do arrays of data for something like cities and states to YellowPages, latitude and longitude to a mapping platform, or anything we need – it’s all about thinking about how the URL structure works on the remote site and planning your “attack.”
WHAT HAVE WE LEARNED TODAY?
- How to go about using
importfor a basic set of required libraries in our Python script - Basic usage of headers and user-agents within our
requests - How to parse simple div’s/containers with the aid of
BeautifulSoup - How to output our results into three different formats (JSON, terminal, or array)
- How to go about improving our basic parser into something more meaningful
IN CLOSING…
This is just a small look into the world of scraping and how to get started, but trust me, it gets complex VERY quickly; scaling multiple parsers across a multidude of domains/servers, storing and managing data, optimizing queries and logic, etc – don’t get me wrong, it’s a blast, but go slow.
At the same time, please make note of something super important – legal implications. Make sure you know what you’re doing, what you’re allowed to do with the data, providing proper attribution if applicable, etc. I’m not a lawyer, so I’m just saying… be smart.
With all of that being said, we’ll circle back to this at a later date with some more detailed / complex ideas, but for now – what are you scraping first?
Hit me up if you run into troubles or just want to chit chat!